Az OpenAI folyamatfelügyeleti modellje sikeresebb a matematikában
Új mérföldkőhöz érkezett az OpenAI legújabb mesterséges intelligencia (AI) modellje: új csúcsteljesítményt ért el a matematikai problémák megoldása terén. Az újítás a folyamatfelügyeleti módszerben rejlik, amelyben az AI minden helyes lépésért jutalmat kap, nem csak a helyes végső válaszért. A kísérleti modellról az OpenAI a weboldalán jelentette be a kutatási eredményeit.
Ez nem csak a teljesítményt növelte, hanem elősegítette azt is, hogy az AI a gondolkodási folyamatot ember által jóváhagyott módon végezze el.A nagy nyelvi modellek képesek bonyolult többlépéses következtetéseket végrehajtani, de a jelenlegi legjobb modellek is tartalmaznak olyan hibákat, amelyeket gyakran hallucinációknak neveznek. hallucinációk csökkentése kulcsfontosságú lépés az AI irányításának fejlesztésében.
Hirdetés:

Az OpenAI két módszert használt a hallucinációk detektálására: az eredményfelügyeletet, amely a végső eredmény alapján ad visszajelzést, és a folyamatfelügyeletet, amely minden egyes gondolkodási lépésre ad visszajelzést. A folyamatfelügyelet jelentősen jobb teljesítményt eredményezett, még az eredmények alapján is.
A folyamatfelügyelet több előnnyel is rendelkezik az eredményfelügyelettel szemben. Közvetlenül jutalmazza a modellt az ember által jóváhagyott gondolkodási folyamat követéséért, mivel minden lépés pontos értékelést kap. A folyamatfelügyelet valószínűbb, hogy érthető következtetéseket hoz létre, mivel a modellt arra ösztönzi, hogy ember által jóváhagyott folyamatot kövessen. Ezzel szemben az eredményfelügyelet jutalmazhatja az irányítatlan folyamatot, és általában nehezebb ellenőrizni.
Egyes esetekben a biztonságosabb AI módszerek csökkenthetik a rendszer eredeményességét és pontosságát, amit irányítási adónak neveznek. Azonban a folyamatfelügyelet negatív irányítási adót eredményez, legalábbis a matematika területén, ami növelheti a folyamatfelügyelet hatékonyságát.
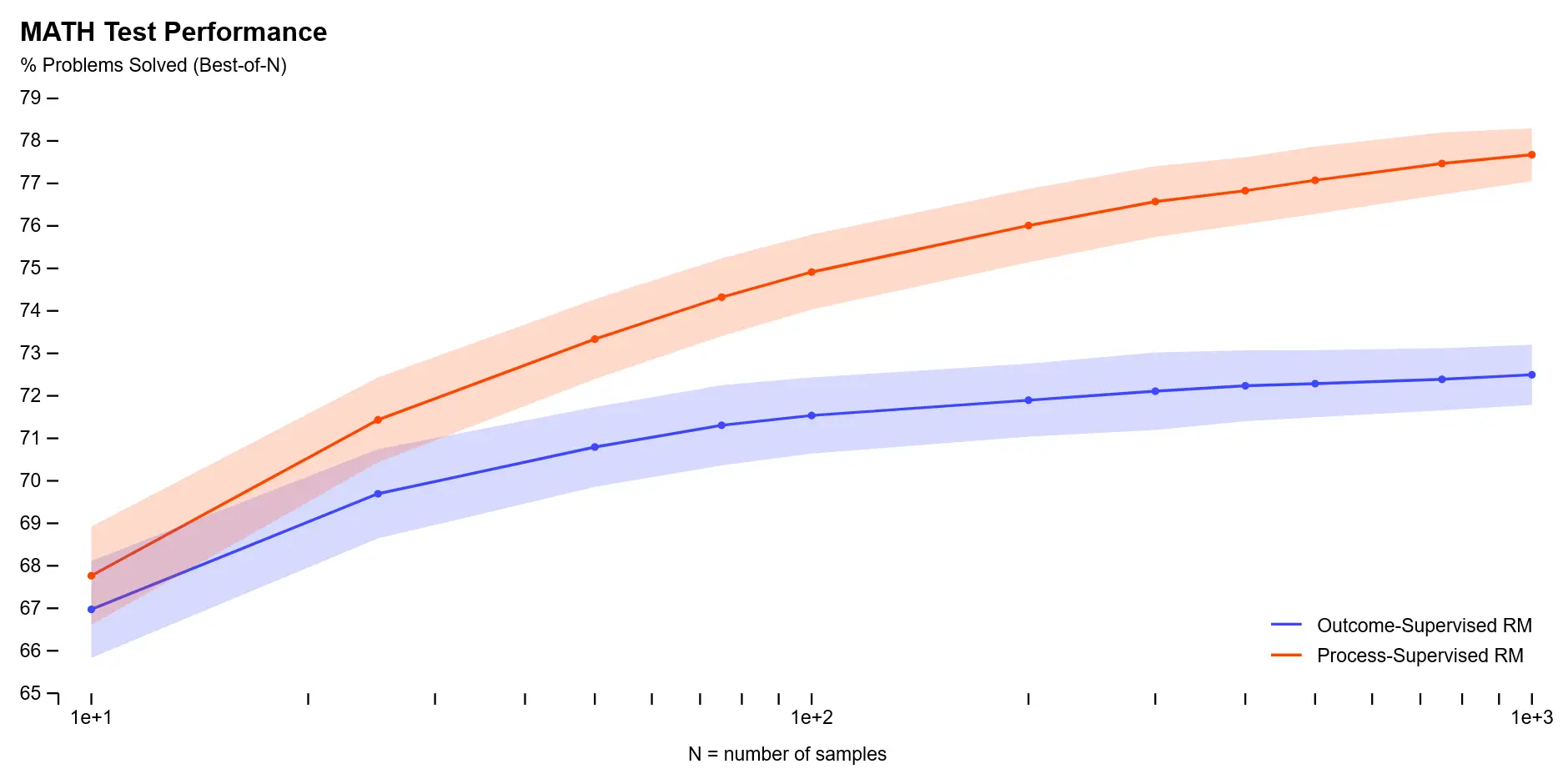
A folyamatfelügyeletet és az eredményfelügyeletet használó jutalommodelleket a MATH teszthalmaz problémáinak használatával értékelték ki. Sok megoldást generáltak minden problémára, majd kiválasztották a legmagasabb rangú megoldást minden jutalommodell szerint. A folyamatfelügyeleti jutalommodell nem csak jobban teljesített általánosságban, de a teljesítménykülönbség nőtt, ahogy több megoldást vizsgáltak minden problémára. Ez azt mutatja, hogy a folyamatfelügyeleti jutalommodell sokkal megbízhatóbb.
A kutatás szerzői az új modellt bemutató cikkben bemutatnak egy példát, ahol a modell sikeresen megold egy komplex trigonometriai problémát. A modell számos trigonometriai azonosságot alkalmaz, és a folyamatfelügyelet segítségével helyes választ ad a problémára.
Bár ezek a módszerek jól működnek a matematika területén, még nem ismert, hogy mennyire lesznek általánosíthatók más területekre. Az OpenAI folytatja a kutatásokat és a fejlesztéseket, hogy tovább finomítsa és kiterjessze ezeket a technikákat, remélve, hogy további előrelépéseket érhet el az AI irányítás területén.


